Distributed Systems
created: 14 May 2021
modified: 19 December 2021
revision: 4
- Rancher + Rancher OS for Docker and Kubernetes
- CoreOS designed with Docker in mind - well optimized Linux for Docker
- Hystrix, Suro, Riemann, Prometheus + , Kibana
- Raft Consensus Algorithm, see http://thesecretlivesofdata.com/raft
- https://jaspen.io distributed system testing. see also hazelcast github with it.
- (Kleppmann, 2017; Rivers, 2017)
CAP
- (Fedosov, n.d.)
- Only 2 of these can be chosen (in practice either AP or CP)
- consistency - all nodes will see same data
- availability - fastest availability, ignoring accuracy
- Partition tolerance - survive network failures
Measurements
- throughput: requests per second, or total time to run a job
- latency: wait to process time (e.g. request is latent, awaiting service)
- response time: time to process + network delay + queueing delay + etc.
- read/write ration: think of where most work will be done
- (Newman, 2015) Underlying OS
- (Newman, 2015) CPU per service, per Application, per Node (if more than 1)
Logging
- [me] External and Centralized
- (Newman, 2015) Standardize: how, where and output format of logging.
- (Newman, 2015) Use correlation IDs to track the request in all services
- (Newman, 2015) Use a query tool, add alerts
- [me] Timestamps for in/out
- [me] Dynamically changeable logging level (e.g. with settings file)
App Level [me]
- profiling
- method/call
- execution time
- N of calls (frequency)
- who calls + execution paths
Design Advices
- Think of where most of work will be done (based on read/write ration)
Time, Order and Causality
- (Fedosov, n.d.) Logical clocks are not about actual time, it’s about an order of events (about partial order?), where events are connected by a happens-before relation.
- Lamport timestamps
- Vector Clocks
- Concurrent Operations and Causality: An operation A happens before another operation B if B knows about A, or depends on A, or builds upon A in some way. Whether one operation happens before another operation is the key to defining what concurrency means. In fact, we can simply say that two operations are concurrent if neither happens before the other, i.e. neither knows about the other. Thus, whenever you have two operations A and B, there are three possibilities: either A happened before B, or B happened before A, or A and B are concurrent.
- Although causality is an important theoretical concept, actually keeping track of all causal dependencies can become impractical. In many applications, clients read lots of data before writing something, and then it is not clear whether the write is causally dependent on all or only some of those prior reads. Explicitly tracking all the data that has been read would mean a large overhead. However, there is a better way: we can use sequence numbers or timestamps to order events.
- Causality and achieving consensus
- see also Transaction, Isolation and Consensus Algorithms and Distributed Lock
- compare-and-set register
- atomic transaction commit in DB
- Locks and leases
- membership/coordination service - system must decide which nodes are alive and up-to-date
- uniqueness constraint to decide which ones will violate constraints
- total-order broadcast: 1) no-messages are lost 2)same order for every node.
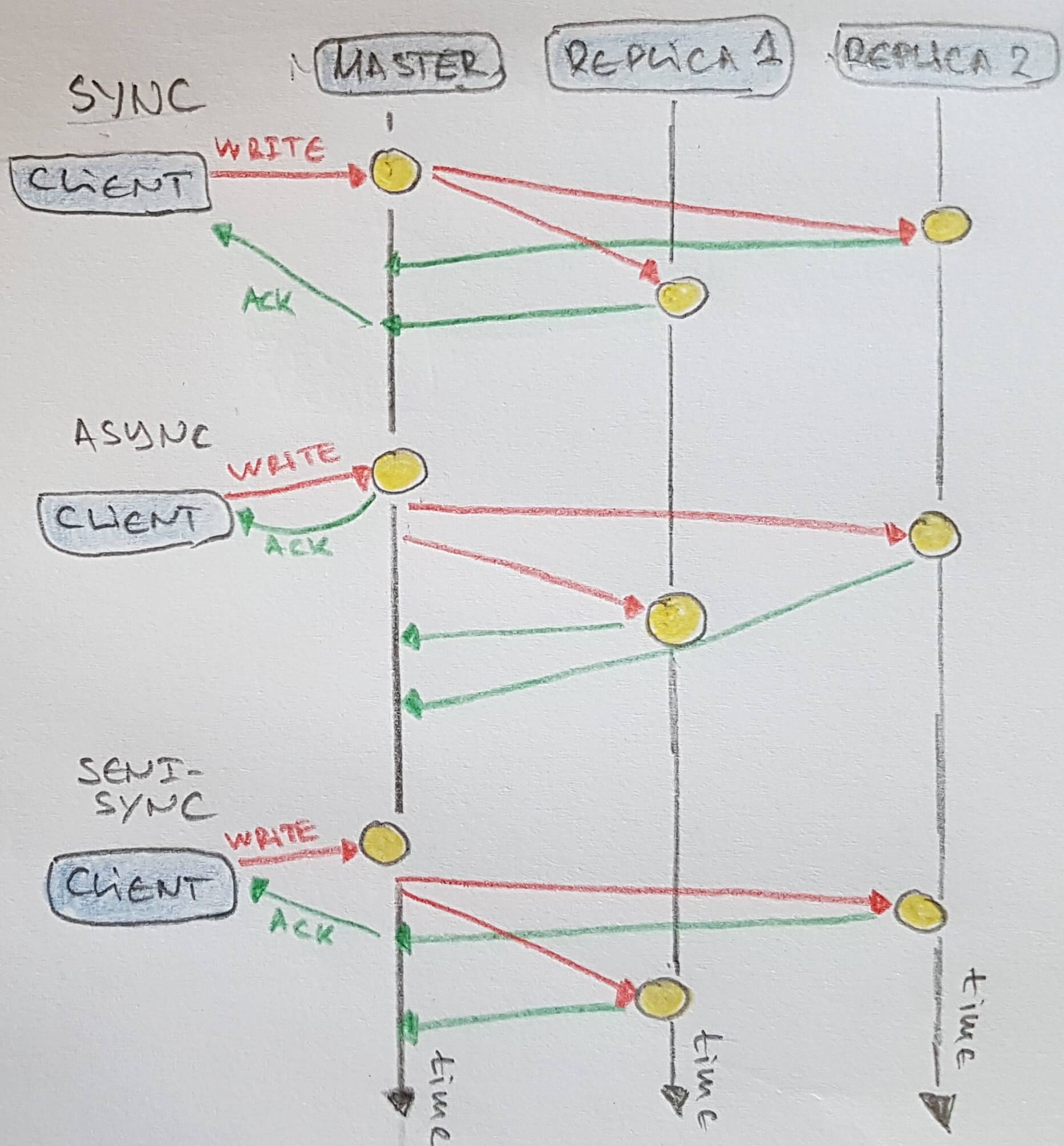
Synchronicity and Consistency
- Synchronous- data is written to all nodes, and only then acknowledged to client. Impractical as one node outage could halt the whole system.
- Semi-Synchronous - usually means that one of the followers is synchronous, and the others are asynchronous. If the synchronous follower becomes unavailable or goes slow, one of the asynchronous followers is made synchronous.
- Asynchronous + eventual consistency - client receives acknowledgement after master handles the data. Copy to replicas is done asynchronous.
- if you stop writing and wait a while - followers will eventually catch up
- Strong consistency - all nodes see values in the same order.
- Causal - read order matches write order of causal related events.
- Weak - all nodes may not see the same order
- Monotonic read consistency - if client makes several reads in order, time will not go backwards. Achievable by ensuring reads are done from the same replica. But different users can read from different replicas.
- eventual consistency
Consensus Algorithms [me]
- 2-phase commit
- coordinator sends a commit query to all participants
- participants execute transaction up to commit point, and write entries to their redo and undo logs
- participants reply with agreement/abort messages
- if all YES, coordinator sends a commit message
- each participant completes the operation and releases all locks/resources
- if NO, coordinator sends a rollback message
- each participant undoes the transaction and releases all locks/resources
- each participant sends an acknowledgement to the coordinator
- coordinator completes transaction when all acknowledgements are received.
- PAXOS
- RAFT used by Hazelcast
Replication
- (Burns et al., 2019) Replica: each replica has all data (useful for stateless services)
- (Burns et al., 2019) Sharding: each shard is only capable of serving a subset of all requests. (useful for stateful services)
- (Burns et al., 2019) Scatter/Gather: Each replica does a small amount of processing and then returns a fraction of the result to the root. The root server then combines the various partial results together to form a single complete response to the request and then sends this request back out to the client.
- Scatter/gather can be seen as sharding the computation necessary to service the request, rather than sharding the data (although data sharding may be part of it as well).
- Single-leader replication: Clients send all writes to a single node (the leader), which sends a stream of data change events to the other replicas (followers). Reads can be performed on any replica, but reads from followers might be stale.
- Multi-leader replication: Clients send each write to one of several leader nodes, any of which can accept writes. The leaders send streams of data change events to each other, and to any follower nodes.
- Leaderless replication: Clients send each write to several nodes, and read from several nodes in parallel in order to detect and correct nodes with stale data.
Partitioning
- Key range partitioning This has the advantage that efficient range queries are possible, but there is a risk of hot spots if the application often accesses keys that are close together in the sorted order. In this approach, partitions are typically re-balanced dynamically, by splitting the range into two sub-ranges when a partition gets too big.
- Hash partitioning, where a hash function is applied to each key, and a partition owns a range of hashes. This destroys the ordering of keys, making range queries inefficient, but may distribute load more evenly. When partitioning by hash, it is common to create a fixed number of partitions in advance, to assign several partitions to each node, and to move entire partitions from one node to another when nodes are added or removed.
- 2nd index
- Document-partitioned index: the secondary indexes are stored in the same partition as the primary key and value. This means that only a single partition needs to be updated on write, but a read of the secondary index requires a scatter/gather across all partitions.
- Term-partitioned index (global index): the secondary indexes are partitioned separately, using the indexed values. An entry in the secondary index may include records from all partitions of the primary key. When a document is written, several partitions of the secondary index need to be updated; however, a read can be served from a single partition.
- Logical Partitioning partition data on nodes, depending on specific logic
- Partial (or Vertical) each node keeps partial information about each object (e.g. some attributes)
Transaction, Isolation
- Read committed ensures that
- only committed data is overwritten (no dirty writes)
- only committed data is read (no dirty reads)
- snapshot isolation, also known as multiversion concurrency control (MVCC) - each transaction sees the data from the time when that transaction started.
- Optimistic - instead of blocking if something potentially dangerous happens, transactions continue anyway, in the hope that everything will turn out alright. When a transaction wants to commit, the database checks whether anything bad happened (i.e. whether isolation was violated); if so, the transaction is aborted and has to be retried. Only transactions which executed serializably are allowed to commit.
- On top of snapshot isolation, SSI adds an algorithm for detecting serialization conflicts among writes, and determining which transactions to abort.
- (see “Serializable snapshot isolation (SSI)” on page 252)
- serializable isolation, the strongest one. It guarantees that even though transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially, without any concurrency.
- (see “Actual serial execution” on page 243)
- 2-phase lock (me - similar to read/write lock)
- Several transactions can have a lock in shared mode simultaneously, unless no transaction has exclusive lock.
- to write - get exclusive lock, but when switching to read, can have shared lock.
- transaction must hold the lock until it is finished (commit or abort), where the 2-phase comes from.
- (see “Two-phase locking (2PL)” on page 248)
References
- Burns, B., Hightower, K., & Beda, J. (2019). Kubernetes: up and running.
- Fedosov, D. Distributed systems cheat sheet. Retrieved January 31, 2021, from http://dimafeng.com/2016/12/04/distributed-systems/
- Kleppmann, M. (2017). Designing data-intensive applications. O’Reilly Media.
- Newman, S. (2015). Building microservices. O’Reilly Media.
- Rivers, A. (2017). Best Practices for Tracing and Debugging Microservices. https://dzone.com/articles/best-practices-for-tracing-and-debugging-microserv