Kafka
created: 18 January 2021
revision: 1
Zookeeper
- Apache Curator for Distributed Synchronization
Definitions
- message
byte[] messagebyte[] key(optional), used for choosing a partition. example: key.hash() modulo NOfPartitions = partitionToUse- NOTE: changing the number of partitions will cause issues
- NOTE: errors when a partition is not available for some reason.
int offset, unique value per partition added from Kafka
- batch a collection of messages
- typically compressed
- tradeoff between batch size and time to process a message (latency vs throughput)
- sent as a wrapper message that is decompressed by consumers

- topic (messages are categorized into topics)
- broken down into 1+ partitions
- time order is NOT GUARANTEED in the topic, but is GUARANTEED inside each partition
- partition FIFO queue
- stored on single disc
- but can be replicated on different servers/brokers
- still one is designated as a leader
- only if leader is unavailable, a new one is chosen
- time order within is GUARANTEED
- segment
- partitions are split into segments (e.g. files). When a file size is hit, a new one is started.
- the current one is called active segment.
- stream data within a single topic
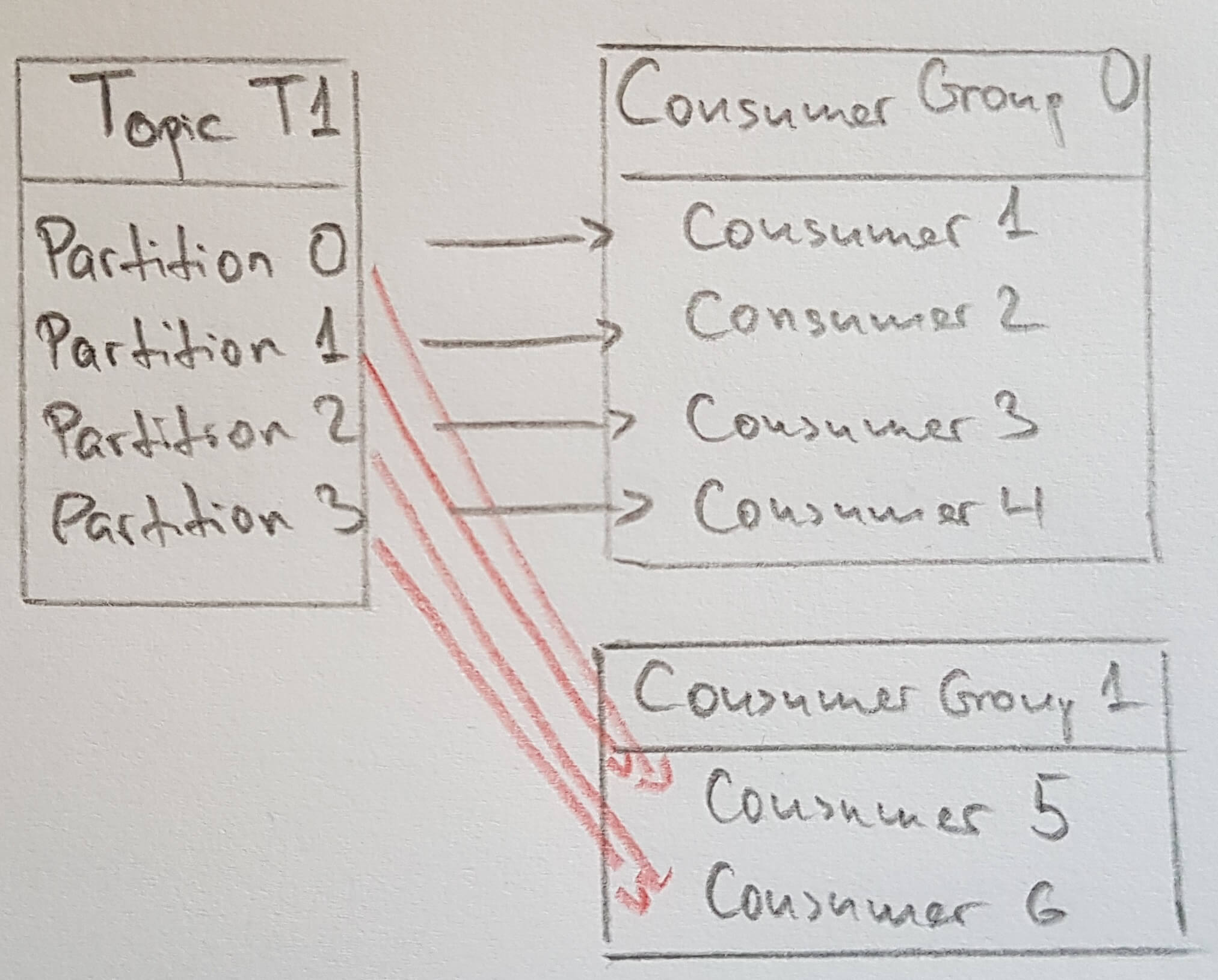
- consumer
- subscribe to 1+ topic , 1+ partitions and reads messages
- keeps track of read messages with the messages’ offset number
- One consumer per thread is the rule!
- consumer group = 1+ consumers
- producer
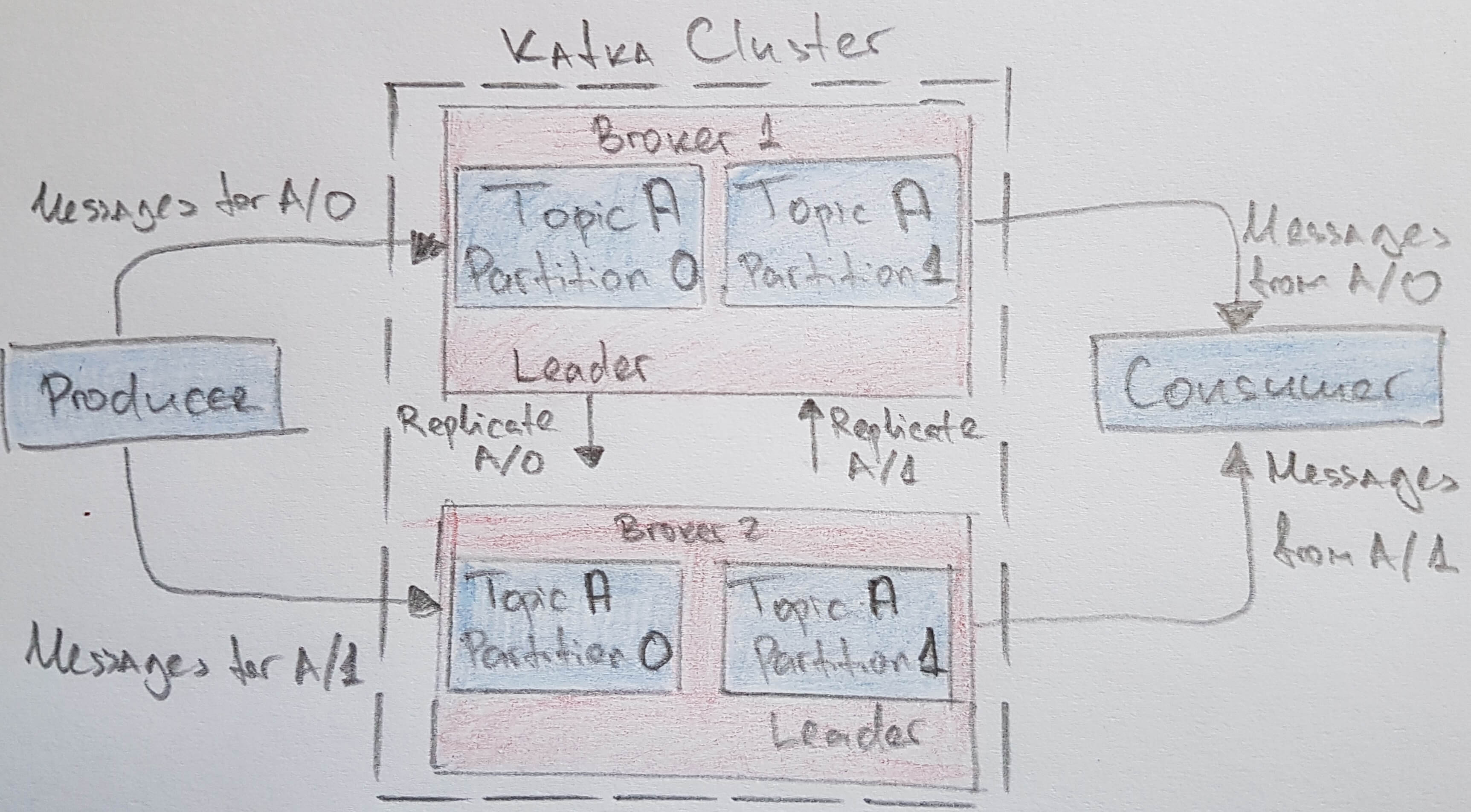
- broker a single Kafka server
- receives messages from producers
- assigns offsets to messages
- commits messages to storage/disk
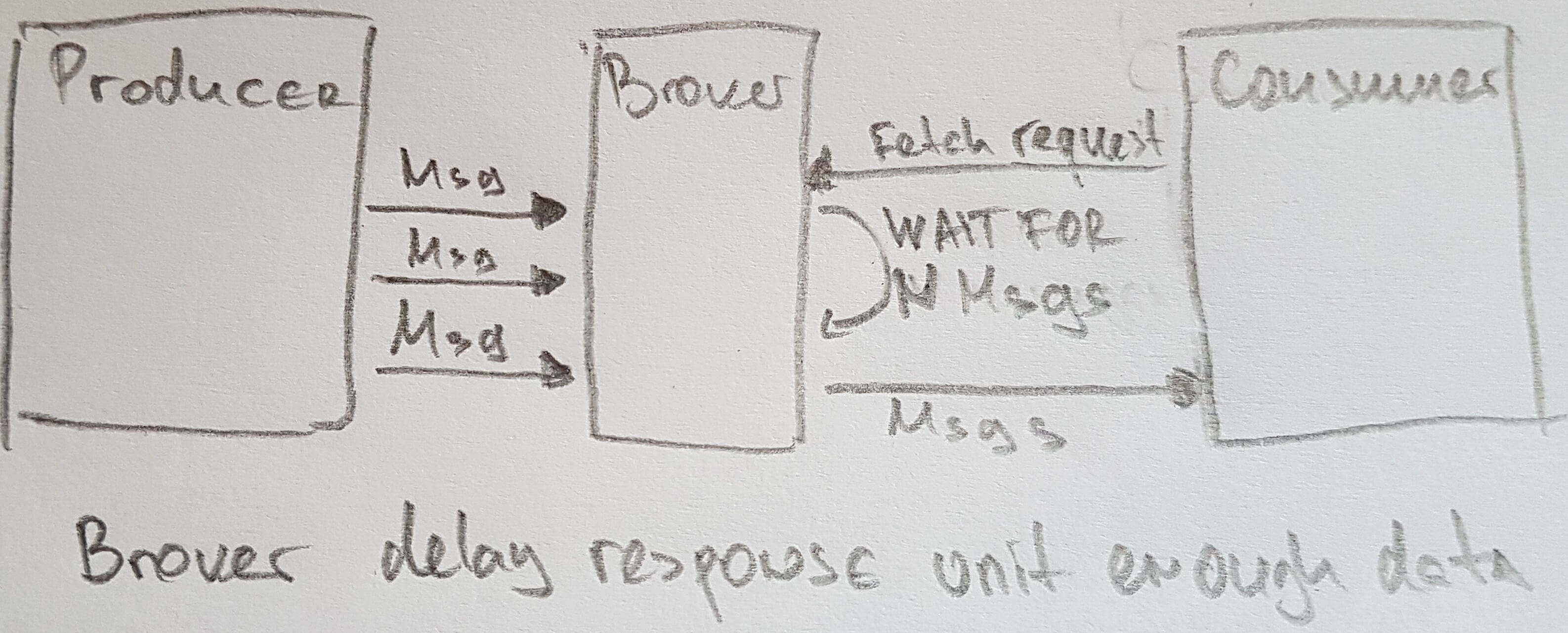
- serves consumers by responding to fetch requests
- Message retention policy
- per topic for either a period of time (e.g. 7 days), or a topic’s max size (e.g. 1GB)
- per topic as log compacted, which will retain only last message with specific key (when only last update is important)
- By default, each segment contains either 1 GB of data or a week of data, whichever is smaller.
Zookeper
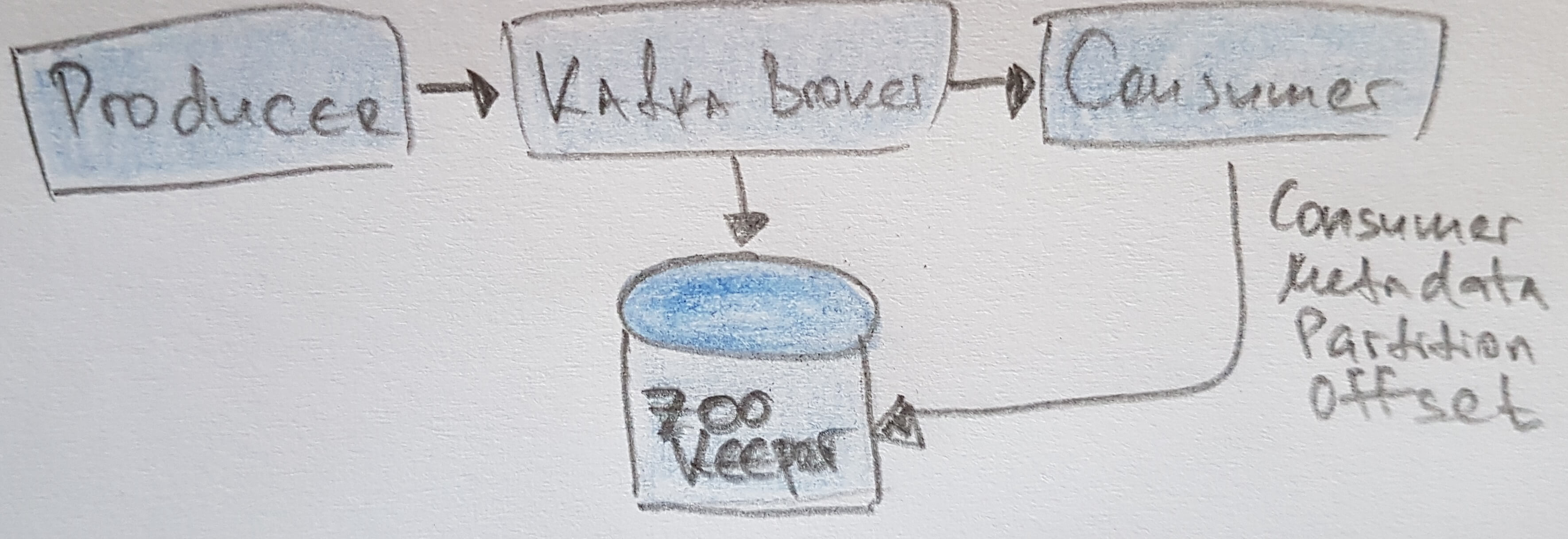
- to store metadata about Kafka CLuster
- to store consumer client details
- consider using a 5-node ensemble, as it needs to tolerate more than one node being down, but not more than 7-nodes due to performance issues
How to Choose the Number of Partitions
- There are several factors to consider when choosing the number of partitions:
- What is the throughput you expect to achieve for the topic? For example, do you expect to write 100 KB per second or 1 GB per second
- What is the maximum throughput you expect to achieve when consuming from a single partition? You will always have, at most, one consumer reading from a partition, so if you know that your slower consumer writes the data to a database and this database never handles more than 50 MB per second from each thread writing to it, then you know you are limited to 60MB throughput when consuming from a partition.
- You can go through the same exercise to estimate the maximum throughput per producer for a single partition, but since producers are typically much faster than consumers, it is usually safe to skip this.
- If you are sending messages to partitions based on keys, adding partitions later can be very challenging, so calculate throughput based on your expected future usage, not the current usage.
- Consider the number of partitions you will place on each broker and available disk space and network bandwidth per broker.
- Avoid overestimating, as each partition uses memory and other resources on the broker and will increase the time for leader elections.
- With all this in mind, it’s clear that you want many partitions but not too many. If you have some estimate regarding the target throughput of the topic and the expected throughput of the consumers, you can divide the target throughput by the expected consumer throughput and derive the number of partitions this way. So if I want to be able to write and read 1 GB/sec from a topic, and I know each consumer can only process 50 MB/s, then I know I need at least 20 partitions. This way, I can have 20 consumers reading from the topic and achieve 1 GB/sec. If you don’t have this detailed information, our experience suggests that limiting the size of the partition on the disk to less than 6 GB per day of retention often gives satisfactory results.
Producer
- see pic 3.1 from book reference
- If we specified a partition in the ProducerRecord, the partitioner doesn’t do anything and simply returns the partition we specified. If we didn’t, the partitioner will choose a partition for us, usually based on the ProducerRecord key. Once a partition is selected, the producer knows which topic and partition the record will go to. It then adds the record to a batch of records that will also be sent to the same topic and partition. A separate thread is responsible for sending those batches of records to the appropriate Kafka brokers. When the broker receives the messages, it sends back a response. If the messages were successfully written to Kafka, it will return a RecordMetadata object with the topic, partition, and the offset of the record within the partition. If the broker failed to write the messages, it will return an error. When the producer receives an error, it may retry sending the message a few more times before giving up and returning an error.
- There are three primary methods of sending messages:
- Fire-and-forget: We send a message to the server and don’t really care if it arrives successfully or not. Most of the time, it will arrive successfully, since Kafka is highly available and the producer will retry sending messages automatically. However, some messages will get lost using this method.
- Synchronous send: We send a message, the
send()method returns aFutureobject, and we useget()to wait on the future and see if thesend()was successful or not. - Asynchronous send: We call the
send()method with a callback function, which gets triggered when it receives a response from the Kafka broker.
- When Order is important
- For some use cases, order is very important. There is a big difference between depositing USD100 in an account and later withdrawing it, and the other way around! However, some use cases are less sensitive. Setting the retries parameter to nonzero and the
max.in.flights.requests.per.sessionto more than one means that it is possible that the broker will fail to write the first batch of messages, succeed to write the second (which was already inflight), and then retry the first batch and succeed, thereby reversing the order. Usually, setting the number of retries to zero is not an option in a reliable system, so if guaranteeing order is critical, we recommend settingmax.in.flights.requests.per.session=1to make sure that while a batch of messages is retrying, additional messages will not be sent (because this has the potential to reverse the correct order). This will severely limit the throughput of the producer, so only use this when order is important.
- For some use cases, order is very important. There is a big difference between depositing USD100 in an account and later withdrawing it, and the other way around! However, some use cases are less sensitive. Setting the retries parameter to nonzero and the
Rebalancing
- rebalancing = moving partition ownership from one consumer to another
- during re-balancing consumers cannot consume messages.
- In addition, when partitions are moved from one consumer to another, the consumer loses its current state; if it was caching any data, it will need to refresh its caches - slowing down the application until the consumer sets up its state again.
- The way consumers maintain membership in a consumer group and ownership of the partitions assigned to them is by sending heartbeats to a Kafka broker designated as the group coordinator (this broker can be different for different consumer groups). As long as the consumer is sending heartbeats at regular intervals, it is assumed to be alive, well, and processing messages from its partitions. Heartbeats are sent when the consumer polls (i.e., retrieves records) and when it commits records it has consumed
- If you are using a new version (0.10.1 or later) and need to handle records that take longer to process, you simply need to tune
max.poll.interval.msso it will handle longer delays between polling for new records. - Will be triggered also when a subscriber is attached to a new topic (e.g. if the
subscribe()method use a regex and a new topic that matches it is started).- Subscribing to multiple topics using a regular expression is most commonly used in applications that replicate data between Kafka and another system.
- Will trigger rebalancing on subscriber
close(), which is a must as it will close connections and sockets
Commits
- commit = the action of updating the current position in the partition a commit
- How does a consumer commit an offset? It produces a message to Kafka, to a special
__consumer_offsetstopic, with the committed offset for each partition. As long as all your consumers are up, running, and churning away, this will have no impact. However, if a consumer crashes or a new consumer joins the consumer group, this will trigger a rebalance. After a rebalance, each consumer may be assigned a new set of partitions than the one it processed before. In order to know where to pick up the work, the consumer will read the latest committed offset of each partition and continue from there. - It is important to remember that
commitSync()will commit the latest offset returned bypoll(), so make sure you callcommitSync()after you are done processing all the records in the collection, or you risk missing messages as described previously. When rebalance is triggered, all the messages from the beginning of the most recent batch until the time of the rebalance will be processed twice. - async commits + see Chapter 4
- A simple pattern to get commit order right for asynchronous retries is to use a monotonically increasing sequence number. Increase the sequence number every time you commit and add the sequence number at the time of the commit to the commitAsync callback. When you’re getting ready to send a retry, check if the commit sequence number the callback got is equal to the instance variable; if it is, there was no newer commit and it is safe to retry. If the instance sequence number is higher, don’t retry because a newer commit was already sent.
- Combining Synchronous and Asynchronous Commits Normally, occasional failures to commit without retrying are not a huge problem because if the problem is temporary, the following commit will be successful. But if we know that this is the last commit before we close the consumer, or before a reba‐ lance, we want to make extra sure that the commit succeeds. Therefore, a common pattern is to combine
commitAsync()withcommitSync()just before shutdown. - Produced messages are considered “committed” when they were written to the partition on all its in-sync replicas (but not necessarily flushed to disk). Producers can choose to receive acknowledgments of sent messages when the message was fully committed, when it was written to the leader, or when it was sent over the network.
- Messages that are committed will not be lost as long as at least one replica remains alive.
- Consumers can only read messages that are committed
Replicas and Partitions (from chapter 5)
- Kafka’s replication mechanism, with its multiple replicas per partition, is at the core of all of Kafka’s reliability guarantees. Having a message written in multiple replicas is how Kafka provides durability of messages in the event of a crash.
- To summarize, Kafka uses Zookeeper’s ephemeral node feature to elect a controller and to notify the controller when nodes join and leave the cluster. The controller is responsible for electing leaders among the partitions and replicas whenever it notices nodes join and leave the cluster. The controller uses the epoch number to prevent a “split brain” scenario where two nodes believe each is the current controller
- we’ve already discussed, data in Kafka is organized by topics. Each topic is partitioned, and each partition can have multiple replicas. Those replicas are stored on brokers, and each broker typically stores hundreds or even thousands of replicas belonging to different topics and partitions. There are two types of replicas: Leader replica Each partition has a single replica designated as the leader. All produce and consume requests go through the leader, in order to guarantee consistency. Follower replica All replicas for a partition that are not leaders are called followers. Followers don’t serve client requests; their only job is to replicate messages from the leader and stay up-to-date with the most recent messages the leader has. In the event that a leader replica for a partition crashes, one of the follower replicas will be promoted to become the new leader for the partition
- Kafka famously uses a zero-copy method to send the messages to the clients. This means that Kafka sends messages from the file (or more likely, the Linux filesystem cache) directly to the network channel without any intermediate buffers. This is different than most databases where data is stored in a local cache before being sent to clients. This technique removes the overhead of copying bytes and managing buffers in memory, and results in much improved performance.
- On Linux, the messages are written to the filesystem cache and there is no guarantee about when they will be written to disk. Kafka does not wait for the data to get persisted to disk—it relies on replication for message durability.
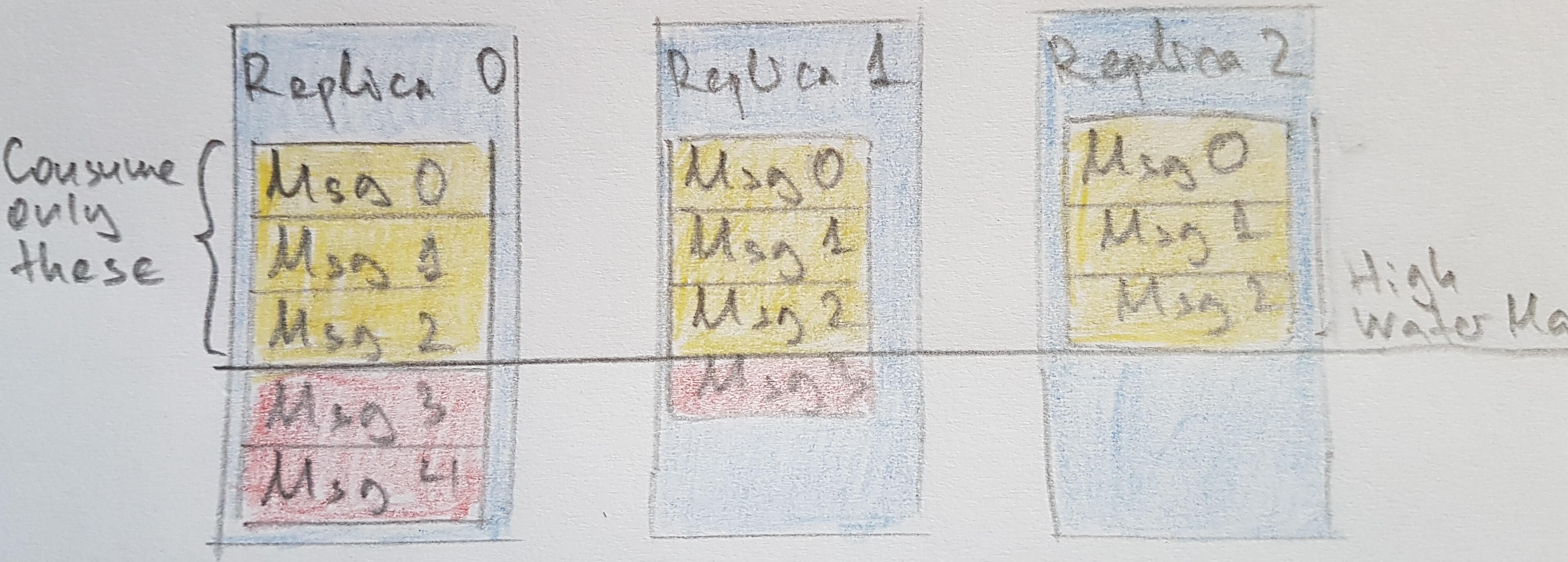
- The basic storage unit of Kafka is a partition replica. Partitions cannot be split between multiple brokers and not even between multiple disks on the same broker. So the size of a partition is limited by the space available on a single mount point. (A mount point will consist of either a single disk, if JBOD configuration is used, or multiple disks, if RAID is configured. See Chapter 2.) When configuring Kafka, the administrator defines a list of directories in which the partitions will be stored—this is the log.dirs parameter (not to be confused with the location in which Kafka stores its error log, which is configured in the log4j.properties file). The usual configuration includes a directory for each mount point that Kafka will use.
- The active segment is never deleted, so if you set log retention to only store a day of data but each segment contains five days of data, you will really keep data for five days because we can’t delete the data before the segment is closed. If you choose to store data for a week and roll a new segment every day, you will see that every day we will roll a new segment while deleting the oldest segment - so most of the time the partition will have seven segments. A Kafka broker will keep an open file handle to every segment in every partition—even inactive segments. This leads to an usually high number of open file handles, and the OS must be tuned accordingly.
Serializers
- AVRO is the recommended one.
From Presentation at Leanplum on Kafka
- One consumer per partition
- Strict message order per partition
- monotonically increasing offset
- Use the power of 2 for partition count
- Keep over partitioning reasonable - not more than 30%
- extract batching in intermediate batching processor
References
- Narkhede, N. (2017). Kafka : the definitive guide. O’Reilly Media.